阅读目录(Content)
前言
上一篇介绍了伪分布式集群的搭建,其实在我们的生产环境中我们肯定不是使用只有一台服务器的伪分布式集群当中的。接下来我将给大家分享一下全分布式集群的搭建!
其实搭建最基本的全分布式集群和伪分布式集群基本没有什么区别,只有很小的区别。
一、搭建Hadoop全分布式集群前提
1.1、网络
1)如果是在一台虚拟机中安装多个linux操作系统的话,可以使用NAT或桥接模式都是可以的。试一试可不可以相互ping通!
2)如果在一个局域网当中,自己的多台电脑(每台电脑安装相同版本的linux系统)搭建,将所要使用的Ubuntu操作系统的网络模式调整为桥接模式。
步骤:
一是:在要使用的虚拟机的标签上右键单击,选择设置,选择网络适配器,选择桥接模式,确定
二是:设置完成之后,重启一下虚拟机
三是:再设置桥接之前将固定的IP取消
桌面版:通过图形化界面设置的。
服务器版:在/etc/network/interfaces iface ens33 inet dhcp #address ...四是:ifconfig获取IP。172.16.21.xxx
最后试一试能不能ping通
1.2、安装jdk
每一个要搭建集群的服务器都需要安装jdk,这里就不介绍了,可以查看上一篇
1.3、安装hadoop
每一个要搭建集群的服务器都需要安装hadoop,这里就不介绍了,可以查看上一篇。
二、Hadoop全分布式集群搭建的配置
配置/opt/hadoop/etc/hadoop相关文件

2.1、hadoop-env.sh
25行左右:export JAVA_HOME=${JAVA_HOME}
改成:export JAVA_HOME=/opt/jdk2.2、core-site.xml
fs.defaultFS hdfs://mip:9000
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
9000:主节点和从节点配置的端口都是9000
2.3、hdfs-site.xml
注意:**:下面配置了几个目录。需要将/data目录使用-R给权限为777。
dfs.nameservices hadoop-cluster dfs.replication 1 dfs.namenode.name.dir file:///data/hadoop/hdfs/nn dfs.namenode.checkpoint.dir file:///data/hadoop/hdfs/snn dfs.namenode.checkpoint.edits.dir file:///data/hadoop/hdfs/snn dfs.datanode.data.dir file:///data/hadoop/hdfs/dn
分析:
dfs.nameservices:在一个全分布式集群大众集群当中这个的value要相同
dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)
一个问题:
dfs.datanode.data.dir:这里我在配置的时候遇到一个问题,就是当使用的这个的时候从节点起不来。当改成fs.datanode.data.dir就有用了。
但是官方给出的文档确实就是这个呀!所以很邪乎。因为只有2.0版本之前是fs
2.4.mapred-site.xml
注意:如果在刚解压之后,是没有这个文件的,需要将mapred-site.xml.template复制为mapred-site.xml。
mapreduce.framework.name yarn
2.5、yarn-site.xml
yarn.resourcemanager.hostname mip yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.local-dirs file:///data/hadoop/yarn/nm
分析:
mip:在主节点的mip就是自己的ip,而所有从节点的mip是主节点的ip。
2.6、创建上面配置的目录
sudo mkdir -p /data/hadoop/hdfs/nn sudo mkdir -p /data/hadoop/hdfs/dn sudo mkdir -p /data/hadoop/hdfs/snn sudo mkdir -p /data/hadoop/yarn/nm
一定要设置成:sudo chmod -R 777 /data
三、全分布式集群搭建测试
3.1、运行环境
有三台ubuntu服务器(ubuntu 17.04):
主机名:udzyh1 IP:1.0.0.5 作为主节点(名字节点)
主机名:server1 IP:1.0.0.3 作为从节点(数据节点)
主机名:udzyh2 IP:1.0.0.7 作为从节点(数据节点)
jdk1.8.0_131
hadoop 2.8.1
3.2、服务器集群的启动与关闭

名字节点、资源管理器:这是在主节点中启动或关闭的。
数据节点、节点管理器:这是在从节点中启动或关闭的。
MR作业日志管理器:这是在主节点中启动或关闭的。
3.3、效果
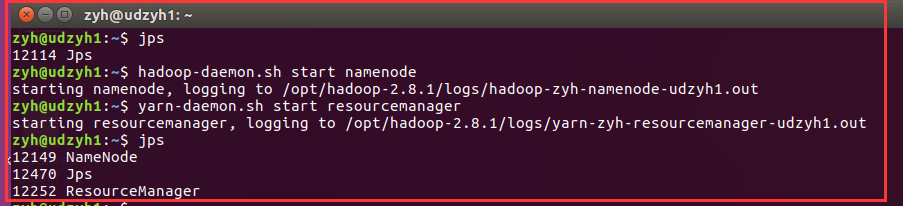
在主节点:udzyh1中
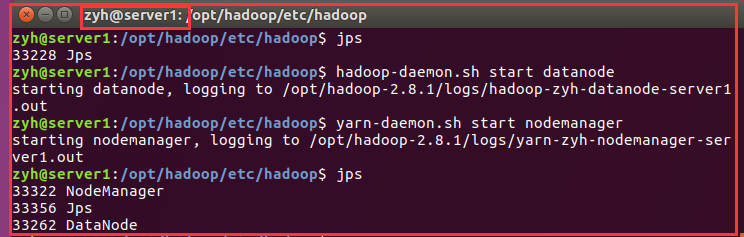
在从节点:server1中
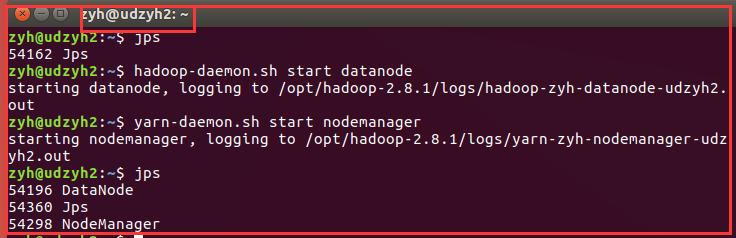
在从节点:udzyh2中
我们在主节点的web控制页面中:http:1.0.0.5:50070中查看到两个从节点
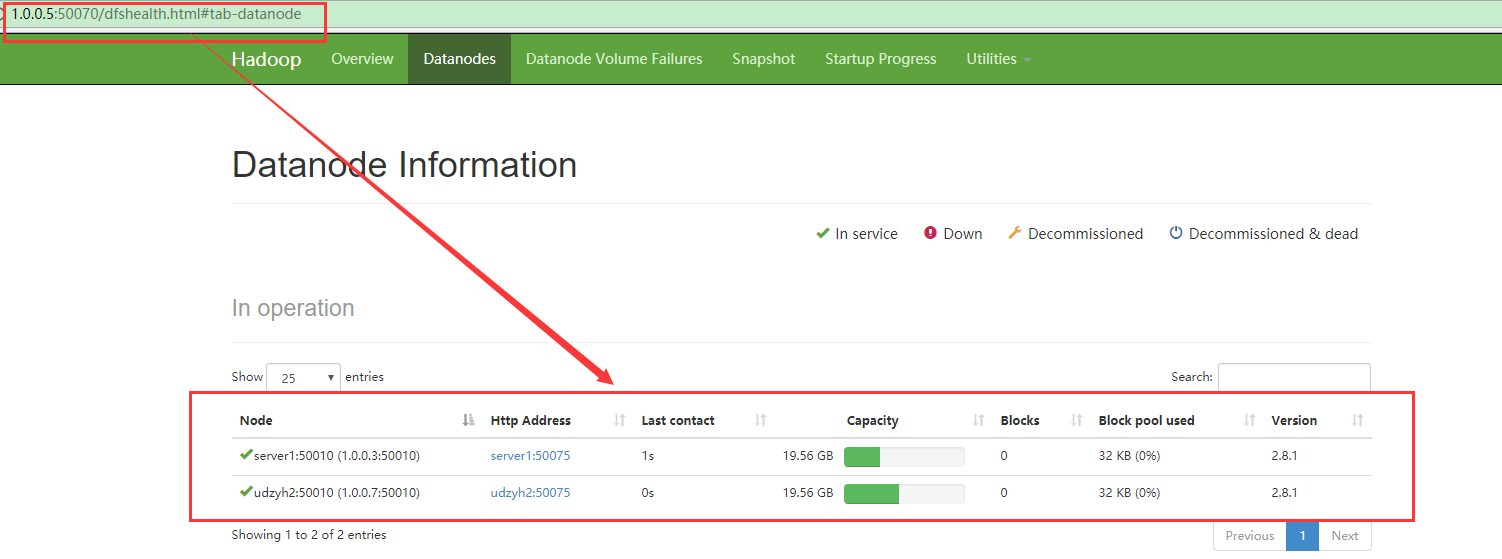
说明配置成功
3.4、监控平台

四、Hadoop全分布式集群配置免密登录实现主节点控制从节点
配置这个是为了实现主节点管理(开启和关闭)从节点的功能:

我们只需要在主节点中使用start-dfs.sh/stop-dfs.sh就能开启或关闭namenode和所有的datanode,使用start-yarn.sh/stop-yarn.sh就能开启或关闭resourcemanager和所有的nodemanager。
4.1、配置主从节点之间的免密登录
1)在所有的主从节点中执行
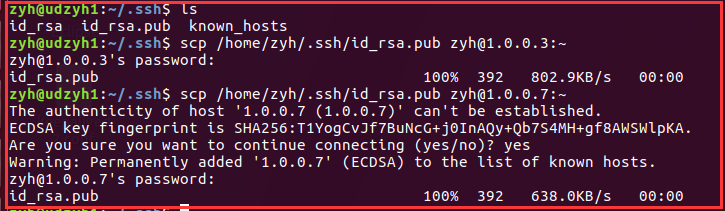
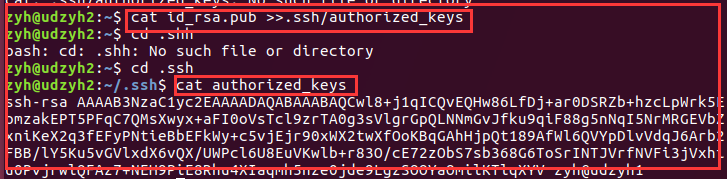
3)在所有的从节点中执行

在从节点1.0.0.7
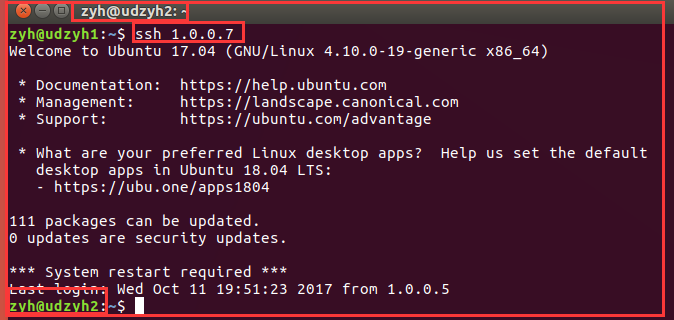
4)测试

我们可以查看他们是用户名相同的,所以可以直接使用ssh 1.0.0.3远程连接
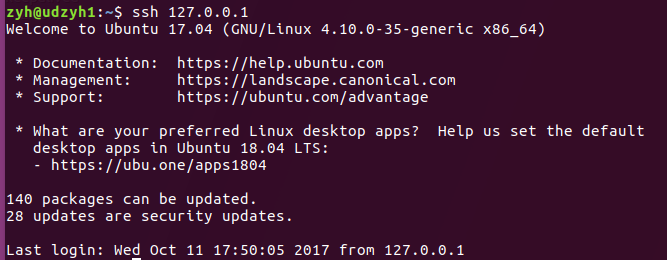
4.2、实现主节点控制从节点
1)在主节点中
打开vi /opt/hadoop/etc/hadoop/slaves

4.3、测试实现主节点控制从节点
1)在主节点的服务器中执行start-dfs.sh

2)在web监控平台查询
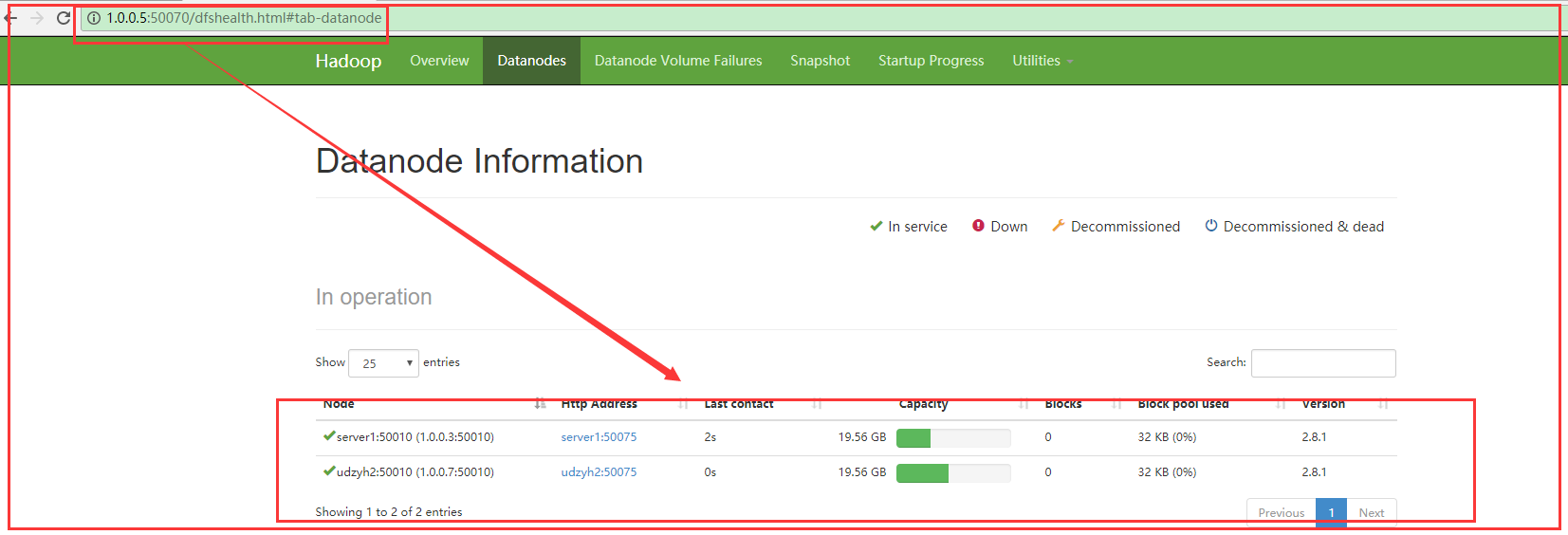
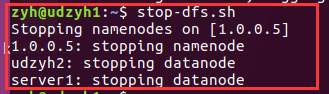
3)在主节点的服务器中执行stop-dfs.sh
3)在主节点的服务器中执行start-yarn.sh

4)在web监控平台查询到
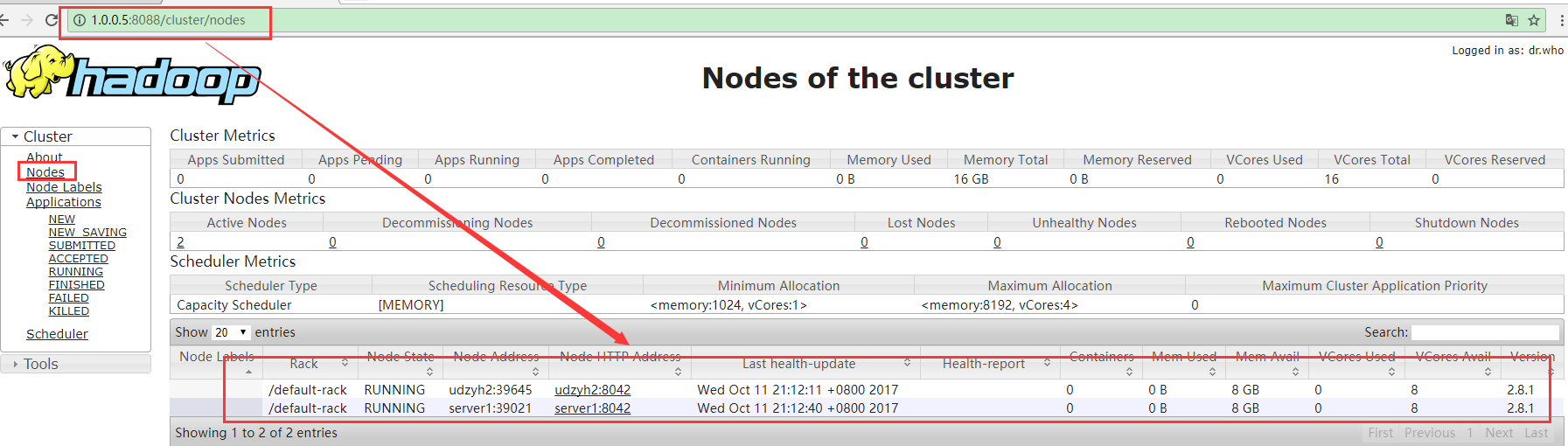
5)在主节点的服务器中执行stop-yarn.sh

五、配置集群中遇到的问题
2)主节点和从节点启动了,但是在主节点的web控制页面查找不到从节点(linux系统安装在不同的物理机上面)
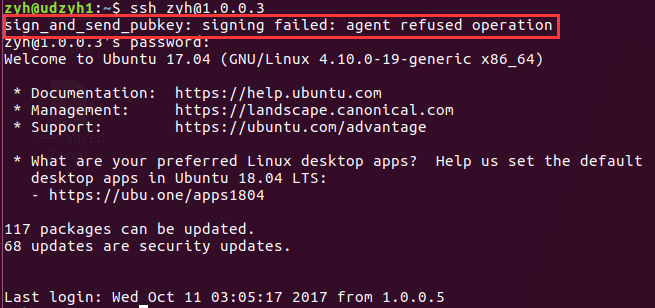
解决方案:
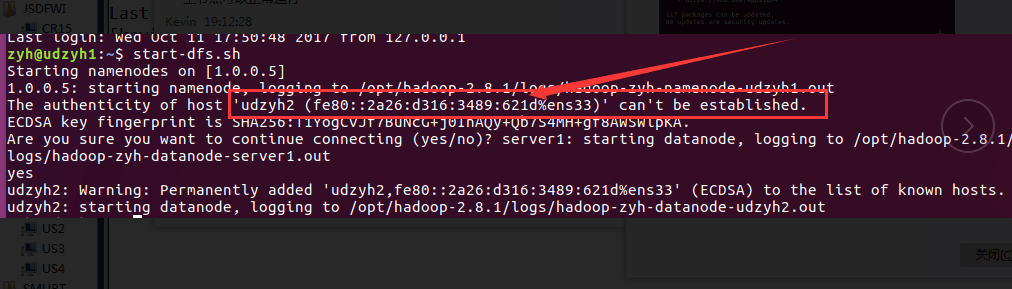
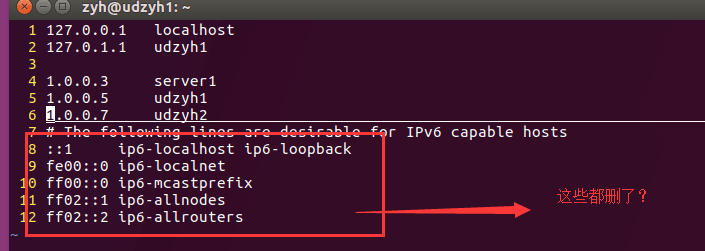
它不能建立IPv6的连接,所以删除了IPv6之后系统会使用IPv4(在主节点上添加从节点的标识的)
4)在主节点的web控制页面查询不到从节点信息(但是使用jps可以查询到)